Introduction
Conversational AI has always faced a stark trade-off: either respond fast with shallow answers or respond smartly with noticeable delays. The KAME architecture from Sakana AI bridges this gap. By running a direct speech-to-speech (S2S) model and a large language model (LLM) in parallel, KAME delivers near-zero latency while injecting rich knowledge in real time. This guide walks you through the key design steps to replicate KAME’s tandem approach, from understanding the baseline trade-offs to implementing the four-stream oracle system. Whether you are building a voice assistant or a real-time chatbot, these steps will help you achieve both speed and intelligence.
What You Need
- Basic knowledge of speech processing (ASR, TTS) and transformer architectures.
- Familiarity with the Moshi direct S2S model (e.g., its three-stream design).
- Access to a streaming speech-to-text (STT) component and a capable LLM (any frontier model).
- Development environment for building and deploying audio token pipelines (e.g., Python, PyTorch, or similar frameworks).
- Real-time audio tools for handling audio tokens at ~80 ms intervals.
Step-by-Step Guide
Step 1: Understand the Two Dominant Paradigms and Their Trade-offs
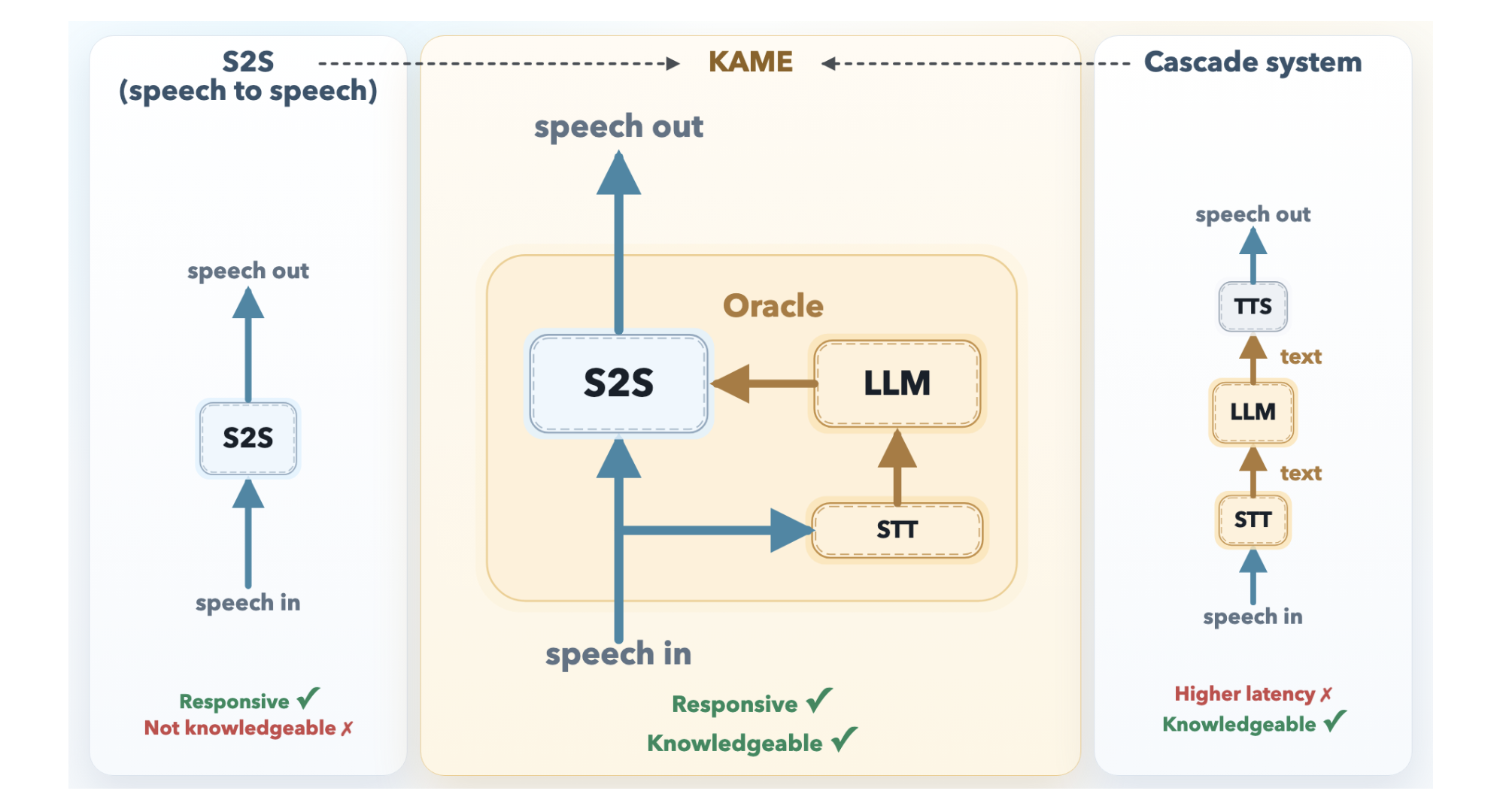
Before designing your tandem system, you must appreciate why direct S2S and cascaded architectures fall short alone. Direct S2S models (like Moshi) process audio tokens continuously, starting to speak almost instantly. However, they allocate most of their capacity to modeling paralinguistic features (tone, emotion, rhythm), leaving little room for factual knowledge. Cascaded systems separate speech recognition (ASR), LLM reasoning, and text-to-speech (TTS). They excel at knowledge but suffer median latencies of about 2.1 seconds—enough to break natural flow. KAME’s innovation is to run both simultaneously, overcoming each paradigm’s weakness.
Step 2: Set Up the Front-End Direct S2S Module
Start with a fast, monolithic S2S model like Moshi. Configure it to process discrete audio tokens in cycles of approximately 80 milliseconds. This module will be your “fast path” that begins generating a spoken response immediately, without waiting for any external system. At this stage, the front-end produces a preliminary response that may be shallow but very fast.
Step 3: Implement the Back-End LLM Module with Streaming STT
Separately, build a back-end pipeline that continuously transcribes user speech using a streaming speech-to-text (STT) component. As the user speaks, the STT extracts partial transcripts and periodically sends them to a full-scale LLM. For each partial transcript, the LLM generates a candidate text response—called an oracle. This oracle represents a more informed answer that the front-end can later incorporate.
Step 4: Extend the Front-End with a Fourth Stream (Oracle Stream)
KAME’s key architectural innovation is adding a fourth stream to Moshi’s original three-stream design (input audio, inner monologue text, output audio). This new stream is the oracle stream. It carries the LLM’s candidate responses in real time. The front-end S2S model now receives both raw audio input and a steady flow of textual knowledge from the back-end. This allows the front-end to “cheat” by peeking at a smarter response while still speaking.
Step 5: Enable Asynchronous Parallel Processing
Ensure that both components run asynchronously. The front-end does not pause for the back-end; the back-end does not block the front-end. The oracle stream updates continuously, and the front-end can choose to use or ignore the latest oracle at any cycle. This asynchronous design is why KAME achieves near-zero latency—the user hears a response almost immediately, and the response gets smarter over time as new oracles arrive (like a “real-time edit” of the spoken reply).
Step 6: Tune the Oracle Injection Mechanism
Not every oracle should override the front-end’s output. Design a decision mechanism (e.g., confidence scoring, semantic similarity, or a learned weight) to decide when to inject the oracle into the output audio stream. If the LLM’s oracle disagrees with the front-end’s preliminary output, the system can smoothly transition from the initial fast response to a more accurate one—sometimes mid-phrase. This requires careful handling to avoid jarring discontinuities.
Step 7: Optimize for Reduced Latency and Natural Flow
Test the system iteratively. Measure end-to-end latency (from user finish to meaningful response start). The goal is to keep latency under 200 ms while still benefiting from LLM knowledge. Also evaluate conversational flow: do users feel the assistant is both intelligent and responsive? Adjust the oracle injection frequency and the update intervals of the streaming STT to balance timeliness vs. quality.
Step 8: Validate and Benchmark Against Traditional Approaches
Compare your tandem system against a direct S2S baseline and a cascaded baseline on standard metrics: response latency, answer accuracy (factual and reasoning), and user satisfaction. KAME’s published results show that the tandem approach achieves latency comparable to direct S2S but with significantly higher knowledge quality—close to that of cascaded systems. Your goal is to replicate this balance.
Tips for Success
- Start simple: Use an off-the-shelf S2S model (e.g., Moshi) and a generic LLM (e.g., GPT-4 via API) for early prototyping. The orchestra stream doesn’t need to be perfect at first.
- Prioritize streaming components: The STT must be capable of incremental transcription. Many cloud ASR services (e.g., Google Speech-to-Text) offer streaming endpoints.
- Handle prosody carefully: When injecting oracle text, preserve the front-end’s paralinguistic features (tone, emotion) to avoid a flat robotic voice. Consider using a neural TTS that can adapt to context.
- Monitor system load: Running two models in parallel can strain hardware. Profile GPU/CPU usage and consider model compression for the front-end.
- Test with diverse queries: Factual questions (e.g., “What is the capital of France?”) stress the oracle quality; open-ended ones (e.g., “Tell me a story”) test the front-end’s creativity. Adjust your injection strategy accordingly.
- Iterate on user feedback: A/B test the system with real users to find the sweet spot between early response and later corrections. Some users prefer a quick “ummm” followed by a refined answer; others find that unnatural.
By following these steps, you can build a voice assistant that feels both instant and intelligent—mirroring the breakthrough that KAME represents. The key is to embrace parallelism, treat latency as a design constraint, and let the LLM inject knowledge while the S2S model maintains the rhythm of human conversation.